
Speech Database for Speech Processing
Abstraction:Address processing is going an emerging engineering which enables interaction of human existences with machines. A world-wide research is traveling to happen out a standard length of a address sample which gives higher public presentation in address processing. Our purpose is to happen an efficient technique or method ensuing effectual address processing application.
Performance of a classifier is a map depends on the length of address sample, environment etc. This work is carried out utilizing mel-frequency cepstral coefficients ( mfcc ) or an efficient characteristic representation vector along with Gaussian Mixture Model ( GMM ) classifier. Consequences are evaluated on our ain database consisting five Indian Languages. This work consists of design, characteristic extraction, station processing and rating of the proposed address database.
Keywords: SI
...LSC, Mel-frequency cepstral coefficients ( MFCC ) , Gaussian Mixture Model ( GMM ) , Expectation Maximization ( EM ) algorithm.
-
Introduction
Address is a natural agencies of communicating for worlds. It is non surprising that worlds can acknowledge the individuality of a individual every bit good as linguistic communication by hearing peculiar address. About 2-3 seconds of address is sufficient for a human to place a talker every bit good as linguistic communication. One reappraisal on human address acknowledgment provinces that many surveies of 8-10 talkers yield truth of more than 97 % if a sentence or more of the address is heard. Performance falls if the length of the address is short and if the figure of talkers is more.
For this ground we have taken different lengths of address sample ( 5 seconds and 10 seconds ) as input to analyse the talker every bit good as linguistic
communication in speech analysis. We can sort the address in two ways: 1. Text-dependent vs. Text-independent address, 2. Noisy address vs. noiseless address. Here we are utilizing Text-independent noiseless address for address analysis.
Till now many research workers have been developed assortment of address databases for analysing the public presentation of address processing. Here we are supplying the address database which is used widely in address processing intent is TIMIT database [ 2 ] , it is the first largest database consists recordings of 630 talkers, each talker reading 10 sentences with typical sentence continuance of 5 seconds merely.
This is deficient for many acknowledgment undertakings. For this ground we manually collected address samples and prepared our ain database ( ILSC ) . The inside informations of ILSC are provided in the following subdivision. On this database we are executing talker and linguistic communication analysis. This work is done by utilizing MFCC [ 4 ] [ 5 ] which represents efficient characteristic vector along with GMM classifier with a combination of Expectation Maximization ( EM ) algorithm [ 1 ] [ 9 ] .
-
Speech Database
Speech samples of the proposed database have been collected by utilizing Prasar Bharathi [ 4 ] from five different linguistic communications viz. ( 1 ) Indian English, ( 2 ) Hindi, ( 3 ) Tamil, ( 4 ) Telugu and ( 5 ) Kannada, we prepared them harmonizing to the linguistic communications and talkers to construct the theoretical account.
The undermentioned figure Fig1 represents the readying of the address samples. Speech database readying involves entering and roll uping the address samples and hive awaying them into a storage database. We have
different resources to enter the address samples and while entering them we have different restraints involved in it, i.e. , recordings can be done in closed environment or unfastened environment ( includes noisy address ) and continuance of the address.
Till now many research workers are prepared different address databases with big figure of talkers by utilizing uninterrupted address samples. For illustration we can see TIMIT database [ 2 ] and it is one of the first largest address database consists recordings of 630 talkers, each talker reading 10 sentences with typical sentence continuance of 5 seconds merely. This is deficient for many acknowledgment undertakings.
For this ground we manually collected address samples from Prasar Bharathi and the recordings are done with mikes, some address samples had speech around 5 proceedingss, staying address samples had speech around 10 proceedingss and every address samples we collected are dwelling of music at the start around 90 seconds and at the terminal about 60seconds in it. We removed the noise content which include music and stored merely the address content into the ILSC database.
We represented the ILSC database in the above figure Fig 1. From beginning we captured the address files and stored them in a storage informations. After that we prepared them harmonizing to the linguistic communication and stored them in storage informations and named them by utilizing their linguistic communication name. In each linguistic communication we have different talkers available so we stored talker 1 into one storage informations and talker 2 into another storage informations until we reach all the talkers stored into their several storage data’s. Here linguistic communication represents the linguistic communication name, talker represents
the talker name, train wave represents the address samples used for developing intent and trial moving ridge represents the address samples used for proving intent.
We have done address processing for five different linguistic communications as we mentioned antecedently. For our convenience the talker name is considered from f1to fn for female talkers and from M1 to mn ( where N is figure of talkers ) for male talkers.
- Preparation of address samples based on linguistic communication
- Preparation of address samples based on talker
- Separated address samples for developing intent and proving intent
In our database we have 15.37 hours of address informations for all the five linguistic communications dwelling of 110 different talkers. For preparation we considered 80 % of address samples and for proving we considered 20 % address samples from each talker severally for talker and linguistic communication analysis. In the below tabular array we are supplying the inside informations of the address informations.
Table I
Detailss of address samples
| S.No. | Language | No of talkers | Length of address considered ( in proceedingss ) | |
| Female | Male | |||
| 1 | Indian-English | 16 | 11 | 204.50 |
| 2 | Hindi | 15 | 12 | 196.35 |
| 3 | Tamil | 10 | 07 | 170.08 |
| 4 | Telugu | 08 | 12 | 174.92 |
| 5 | Kannada | 10 | 09 | 176.91 |
-
System Description
Any Speaker and linguistic communication analysis procedure chiefly involves following stairss: Speech database readying, noise decrease, characteristic extraction, constructing the theoretical account. Now we are traveling to supply description of the mentioned procedure. First measure Speech database readying follows the ILSC database readying. After roll uping speech samples we segmented it into smaller address samples of length 5 seconds and 10 seconds each. After cleavage we have to pull out the characteristics of metameric address samples. To pull out the characteristics and we are utilizing MFCC algorithm to pull out the characteristics of address samples. Here we are pull outing acoustic characteristics of address
samples which include mfcc coefficients, differential characteristics ( a?† ) and acceleration characteristics ( a?†a?† ) of address samples. After pull outing the address samples we need to construct the theoretical account and to make so we used GMM with a combination of EM to make maximal convergence [ 9 ] .
- Pre-processing and Cleavage
In this stage we are traveling to section the address samples into the length of 5 seconds and 10 seconds that which contains merely the address but non the noise. We collected the address samples from Prasar Bharathi [ 3 ] beginning, they are recorded by utilizing mikes. So to take the music and to section address samples into smaller 1s we had done cleavage. As we mentioned there is music at the start and terminal of address samples we neglected the music and considered merely address to section it. To make so, we captured the address sample and read the address informations dwelling of 5 seconds and it with different name and we repeated this procedure until we reach the terminal of the address sample. Equally good as we repeated the same procedure for all address samples.
We have done this procedure until we got 980 segmented address samples of 10sec and 5sec each in each of the linguistic communication. After roll uping speech samples we need to fix them for preparation and proving intent. Here we are utilizing 784 metameric address samples for developing the theoretical account and 196 segmented address samples for proving the theoretical account from each linguistic communication. In Table II we are supplying the inside informations of address principal.
Table III
Detailss of address samples
| Language | No of talkers | Length of
address considered ( in proceedingss ) |
No of segmented samples collected | ||
| Female | Male | female | Male | ||
| English | 16 | 11 | 204.50 | 789 | 351 |
| Hindi | 15 | 12 | 196.35 | 571 | 554 |
| Tamil | 10 | 07 | 170.08 | 704 | 400 |
| Telugu | 08 | 12 | 174.92 | 434 | 639 |
| Kannada | 10 | 09 | 176.91 | 597 | 455 |
- Feature extraction
Feature extraction is the procedure of transforming the address signal in to a set of characteristic vectors. The characteristic vector represents the talker specific information due to vocal piece of land, excitement beginning and behavioral traits. A good characteristic vector set should hold representation of all the constituents of talker information. MFCCs are largely related to the human peripheral auditory system. The chief intent of the MFCC is to mime the behavior of the human ears [ 7 ] . Harmonizing to the surveies, human hearing does non follow the additive graduated table but instead so it follows Mel-spectrum graduated table which is a additive spacing at low frequences below 1 KHz and logarithmic grading at high frequences above 1 KHz to capture the of import features of the address. The figure Fig3 represents the block diagram of MFCC and besides we are supplying brief of mfcc stairss.
ignal
Mel cepstrum
Fig 3: Block diagram of MFCC procedure
- Frame the signal into short frames: We can detect that a speech signal is invariably altering, so to simplify the things we are stand foring the address signal on 25 msecs window and we considered 10 msecs hop clip ( stairss between consecutive Windowss ) of each window.
- Voice activity sensing: To make so we are using Discrete Fourier Transformations of the frames to happen out power spectrum of frames and after that we need to calculate filter bank energies of each frame.
Where is the clip sphere frame, S ( N ) is clip domain signal, I is frame figure, H ( n ) is overacting window
of sample length N, K is the length of DFT.
Whereis power spectrum of frame I.
Formulae for calculating mel-filter bank energies:
Here degree Fahrenheit is frequence and which represents.
- Take the logarithm of all filter bank energies: Once we have the filterbank energies, we need to take the logarithm of them. This is because we do n't hear volume on a additive graduated table, to make so we need to add higher energy about 8 times energy to it. This compaction operation makes our characteristics match more closely what humans really hear. Why we apply this logarithm is because the it allows us to utilize cepstral average minus, which is a channel standardization technique.
- Discrete Cosine Transformations ( DCT ): of all the filterbank energies. Keep the DCT coefficients of 2-13 and fling the remainder. This is because if we have more DCT coefficients so we will acquire fast alterations in the filterbank energies and it degrades the public presentation, so to acquire a little betterment we need to drop them. Here we are supplying the expression for change overing the frequences into mel-frequencies.
- Constructing the theoretical account:In this measure we have to cover with two stages. ( 1 ) Training the theoretical account, ( 2 ) Testing the theoretical account. For this intent we use GMM with combination of EM algorithm. In developing the theoretical account, the extracted characteristics have to be made as mixtures ( groups ) . In proving stage the extracted characteristics of address samples presented in test-wave will be tested with the mixtures which we have made to acknowledge the address informations.
- Gaussian Mixture Model:In cardinal, a mixture
theoretical account is a probabilistic theoretical account which assumes the implicit in information is belongs to a mixture distribution. A Gaussian Mixture Model ( GMM ) is a parametric chance denseness map represented as a leaden amount of Gaussian constituent densenesss that measures uninterrupted characteristics in assorted speech systems [ 8 ] . The parametric quantities of Gaussian mixture theoretical account are average ( µ ) , co-variance matrix ( ? ) and it’s chance denseness map is given by:
Where P ( x ) is probability denseness of ten and x is a information vector. The advantages of the GMMs include flexibleness, general-purposeness and the being of an effectual appraisal algorithm. There are several techniques available for gauging the parametric quantities of a GMM [ 9 ] but most frequently GMMs are estimated utilizing the Expectation-Maximization ( EM ) algorithm [ 10 ] for its maximal convergence appraisal.
- Expectation Maximization algorithm:EM algorithm [ 11 ] [ 12 ] is an iterative algorithm that starts from some initial estimation of parametric quantity or informations set ( e.g. , random ) and so returns to iteratively update the informations set until convergence or maximal likelihood observation is detected. EM algorithm surrogates between two stages viz. E-step ( expectation measure ) and an M-step ( maximization measure ) . In peculiar, EM algorithm efforts to happen the parametric quantities
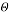 that maximize the log chanceof the ascertained informations. The EM algorithm foremost finds the expected value of the complete informations log-likelihoodwith regard to the unknown informations Y given the ascertained informations Ten and the current parametric quantity estimations until the convergence reaches. That is, we
that maximize the log chanceof the ascertained informations. The EM algorithm foremost finds the expected value of the complete informations log-likelihoodwith regard to the unknown informations Y given the ascertained informations Ten and the current parametric quantity estimations until the convergence reaches. That is, we
define as follows:
Where, are the current parametric quantities estimations that we used to measure the outlook and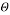 are the new parametric quantities that we optimize to increase dataset ( Z ) .
are the new parametric quantities that we optimize to increase dataset ( Z ) .
- Any GMM application trades with 2 stages, developing the theoretical account and proving the theoretical account. In developing stage, characteristic vector creative activity will be done by utilizing the extracted characteristics of the talkers who are considered for preparation. In which we are using 75 loops to happen out the maximal likeliness parametric quantity appraisal. This procedure is used to organize the mixtures ( here mixtures are nil but bunchs ) of the information parametric quantities. In proving stage, extracted characteristics of the talkers who are considered for proving will be compared with the characteristic vectors which are created in old stage ( GMM developing stage ) .
- Observations
The public presentation of the system is tested against text independent noise less address. Persons who involved in preparation are involved in proving. I am taking at 5 different linguistic communications dwelling of different figure of talkers for talker acknowledgment system. The mean public presentation for 10 seconds wave file is 72.65306 % and for 5sec moving ridge file is 53.67348 % .
Table IV
Concluding consequences of talker analysis
| Langue | No of talkers | Percentage lucifer for 10sec address input | Percentage lucifer for 5sec address input |
| Telugu | 20 | 82.6531 | 47.9592 |
| Hindi | 27 | 78.5714 | 60.2041 |
| English | 29 | 69.3878 | 58.1633 |
| Kannada | 19 | 64.2857 | 45.9184 |
| Tamil | 17 | 68.3673 | 56.1224 |
- Decision
- Mentions
- Andre Gustavo Adami, Automatic Speech Recognition: From the Get downing to the Lusitanian Language, Universidade de Caxias do Sul, Centro de Computacao e Tecnologia district attorney Informacao.
- Rua Francisco Getulio Vargas, 1130, Caxias do Sul, RS 95070-560, Brasil.
- Stephen A. Zahorian, Jiang Wu,
Montri Kamjanadecha, Chandra Sekhar Vootkuri, Brian Wong, Andrew Hwang, Eldar Tokhtamyshev: Open Source Multi-Language Audio Database for Spoken Language Processing Applications.INTERSPEECH 2011: 1493-1496
- Data collection essays
- Graphic Design essays
- Data Mining essays
- Cryptography essays
- Internet essays
- Network Security essays
- Android essays
- Computer Security essays
- World Wide Web essays
- Website essays
- Computer Network essays
- Application Software essays
- Computer Programming essays
- Computer Software essays
- Benchmark essays
- Information Systems essays
- Email essays
- Hypertext Transfer Protocol essays
- Marshall Mcluhan essays
- Virtual Learning Environment essays
- Web Search essays
- Etiquette essays
- Mainstream essays
- Vodafone essays
- Web Search Engine essays
- Networking essays
- Telecommunication essays
- Network Topology essays
- Telecommunications essays
- Programming Languages essays
- Object-Oriented Programming essays
- Java essays
- Normal Distribution essays
- Probability Theory essays
- Variance essays
- Cloud Computing essays
- Computer Science essays
- Consumer Electronics essays
- Data Analysis essays
- Electronics essays
- engineering essays
- Enterprise Technology essays
- Hardware essays
- Impact of Technology essays
- Information Age essays
- Information Technology essays
- Modern Technology essays
- Operating Systems essays
- people search essays
- Robot essays


